Ever since database-driven applications have been used to serve data on the web, users viewing that data have wanted to get at it programmatically. Whether it’s for automatically scouring an auction site for a hard to find classic Nintendo game or getting weather updates for your custom alarm clock application, you will probably start looking for a way to get that data into your program.
In this blog post, I will cover a basic comparison of browsers vs. scrapers, and then dive into some code to show you how to write a simple scraper to get the rating of a movie from IMDB.
Browsers vs. Scrapers
One important thing to realize is that ultimately, a website is often little more than an HTML formatter sitting on top of a database. When a request is made, the website will query data from a database, possibly manipulate it in some interesting way, and then pass the fields to some sort of HTML formatter (like a view engine). This HTML is then returned to the client’s browser as a response. This diagram shows how data is passed through to the browser in a typical HTTP request/response scenario.
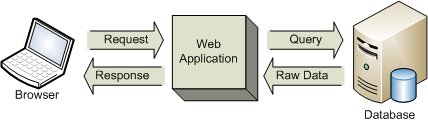
Compare this to a scraper, which is essentially just an automated browser that doesn’t require human interaction to gather the data from the remote server.

As you can see, the only difference is that the application is creating and sending the requests, and then parsing the meaningful data from the responses and persisting it to some data store (in this case a database).
A Simple Scraper
Before diving into code, you will want to investigate the site you want to scrape and figure out what kind of requests their servers are set up to handle. In this case we’ll be scraping http://www.imdb.com/. One thing to note is that IMDB has an API which is much easier to use than trying to scrape the site, but for illustration purposes we’ll assume that no such API exists.
The first thing we’ll do is go to the IMDB website and search for a movie name, in this case I’ll search for Tron: Legacy by typing it into the search box and hitting enter. Immediately I notice the URL at the top of the page: http://www.imdb.com/find?s=all&q=Tron%3A+Legacy. I know that %3A the URL-encoded way of saying “:”, and + is the same as “ “, so I can clearly see that if I visit the URL “http://www.imdb.com/find?s=all&q=” followed by the URL-encoded name of a movie, I should get the search results page.
Note: For the code below to work we’ll need to reference System.Web (which means targetting the full-blown .NET framework, and not just the client profile). If you are targetting the Client Profile you will not see System.Web as an available reference.
And here’s the code:
[csharp]
static Single GetMovieRating(string movieName)
{
var webClient = new System.Net.WebClient();
string searchUrl = “http://www.imdb.com/find?s=all&q=” + HttpUtility.UrlEncode(movieN
string searchResponse = webClient.DownloadString(searchUrl);
throw new NotImplementedException(“This function isn’t done yet!”);
}
[/csharp]
If you examine the string response, you’ll see that it now contains the HTML returned by IMDB. You’ll also notice that the rating is not on this page, because it’s just a search results page. The next step will be to find the URL of the actual movie page which contains the rating that we’re looking for. We could parse out the DOM into an object and traverse through it, which would probably work pretty well in this case. There are downsides to doing this however: it’s very slow when all we want is a single piece of information, it uses a relatively large amount of memory, and it’s also a lot more complicated (code-wise) to do so. Because of that, we’ll just write a simple regular expression to find what we’re looking for.
You may have noticed that there are a few movies beginning with “1.”, followed by an anchor tag referencing the movie page. Instead of searching for one in a specific category (like Popular Titles, Exact matches, etc.), we’ll just search for the first one we find, just in case the user’s search didn’t give us a result in that category.
We’ll use this regex to do so:
[html]
1\..*?href=”(?
[/html]
And the following code:
[csharp]
Match movieUrlMatch = Regex.Match(searchResponse, @”1\..*?href=””(?
if (!movieUrlMatch.Success) return 0.0f;
string movieResponse = webClient.DownloadString(“http://www.imdb.com” + movieUrlMatch.Groups[“MovieLink”].Value);
[/csharp]
Now we have a movieResponse string, containing the HTML of the movie’s page. All we need to do now is create another regex to parse the rating, and then return it to the caller.
[csharp]
Match movieRatingMatch = Regex.Match(movieResponse, @”(?
Single movieRating;
if (!movieRatingMatch.Success || !Single.TryParse(movieRatingMatch.Groups[“Rating”].Value, out movieRating)) return 0.0f;
return movieRating;
[/csharp]
And that’s it! we’ve successfully scraped IMDB to get the rating of a movie. You can now call this function from a GUI or write an app to rename your files by pre-pending the rating to them.
Download source code here.
Upcoming Web Scraping Topics
- Understanding the HTTP request
- Tools & Techniques
- Legal & Ethical Issues
- Common Problems & Challenges